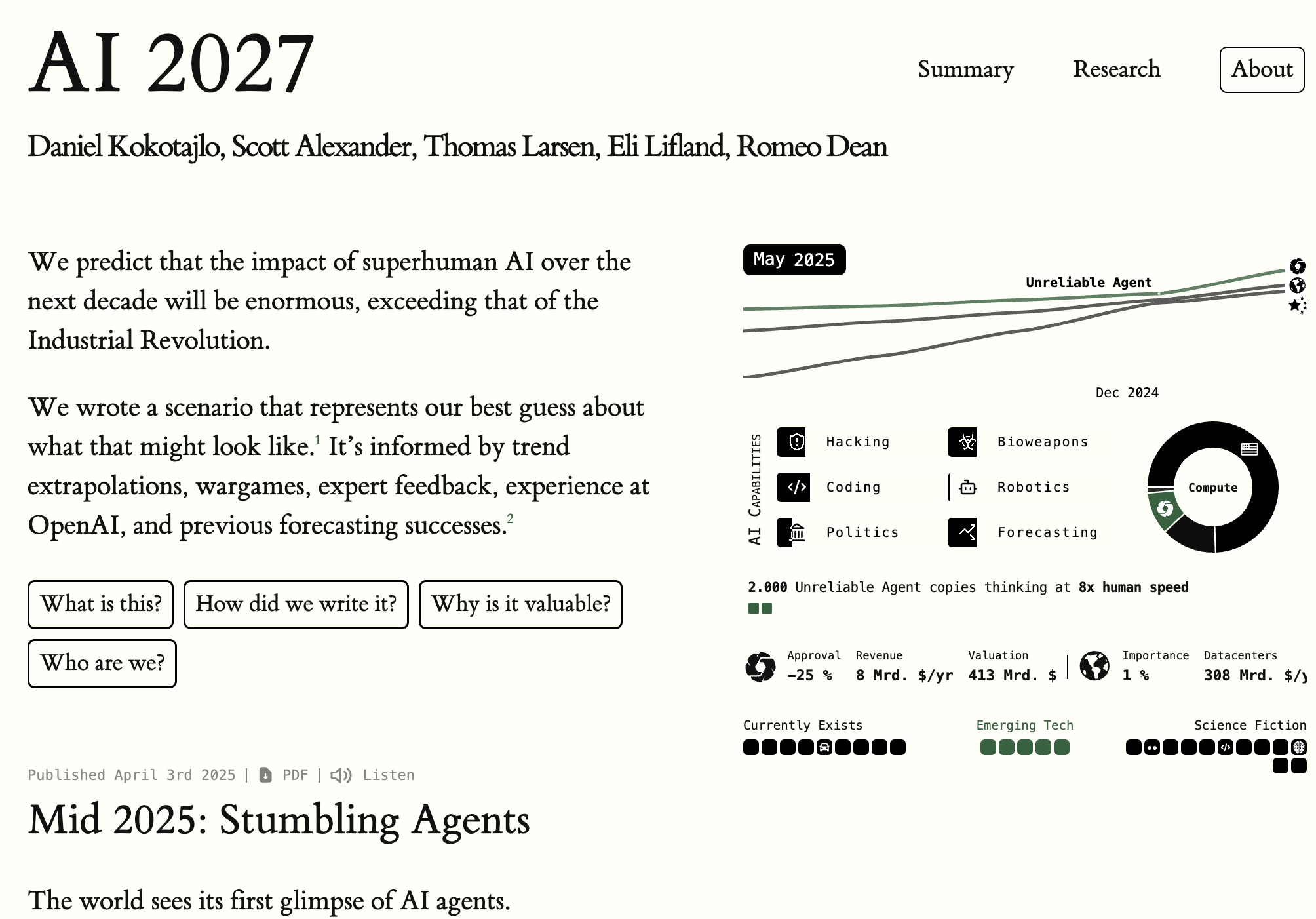
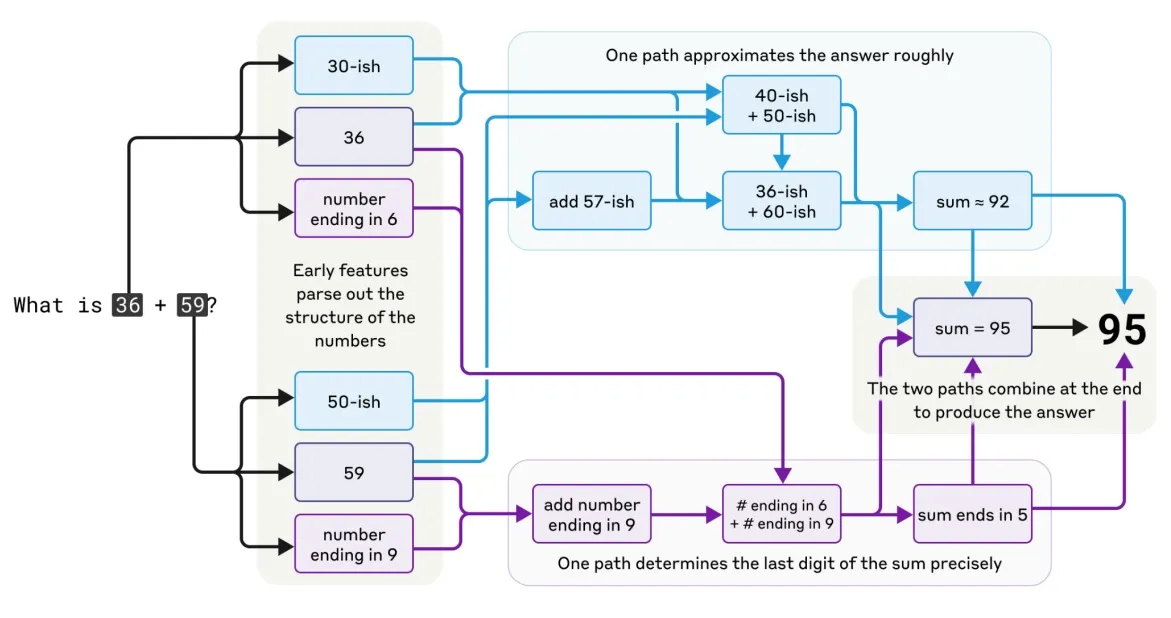
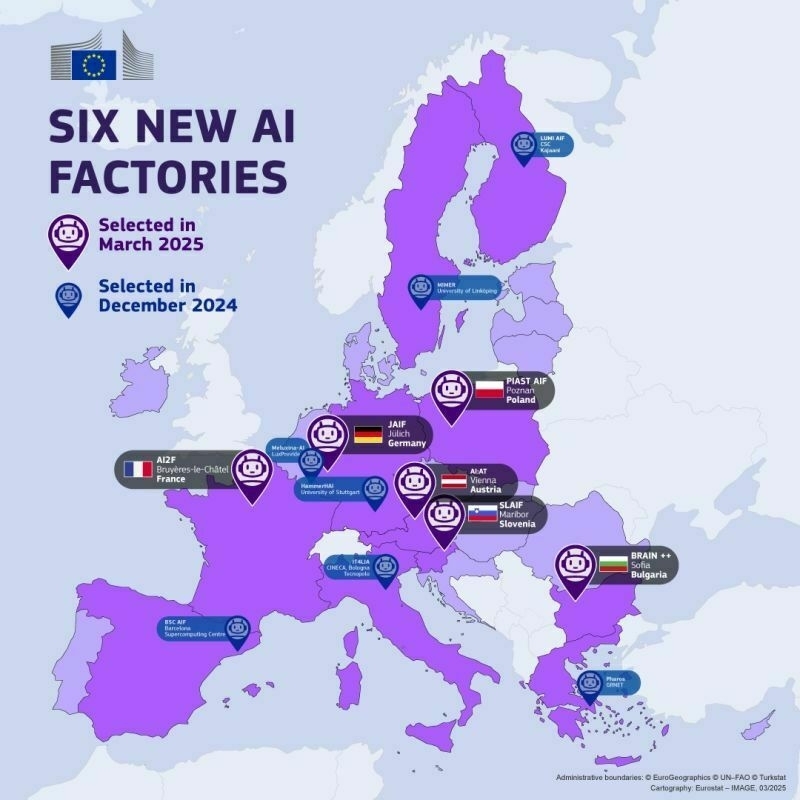
Ever noticed how we struggle with rapid, non-linear change? 🌪️ Fasten your seatbelts, because groundbreaking AI-based developments could make your head spin!
Enter superhuman AI 🤖. Experts predict its impact over the next decade could outstrip the Industrial Revolution. Yeah, you heard right.
The team at AI Futures Project has crafted scenarios backed by trend extrapolations, wargames, expert feedback, and their previous forecasting wins. And the best part? It’s presented in a super intuitive way.
Don’t expect a crystal ball prediction. Think of it as a turbo boost into very near futures!
Great resource to dive in and get those mental gears turning! 💡